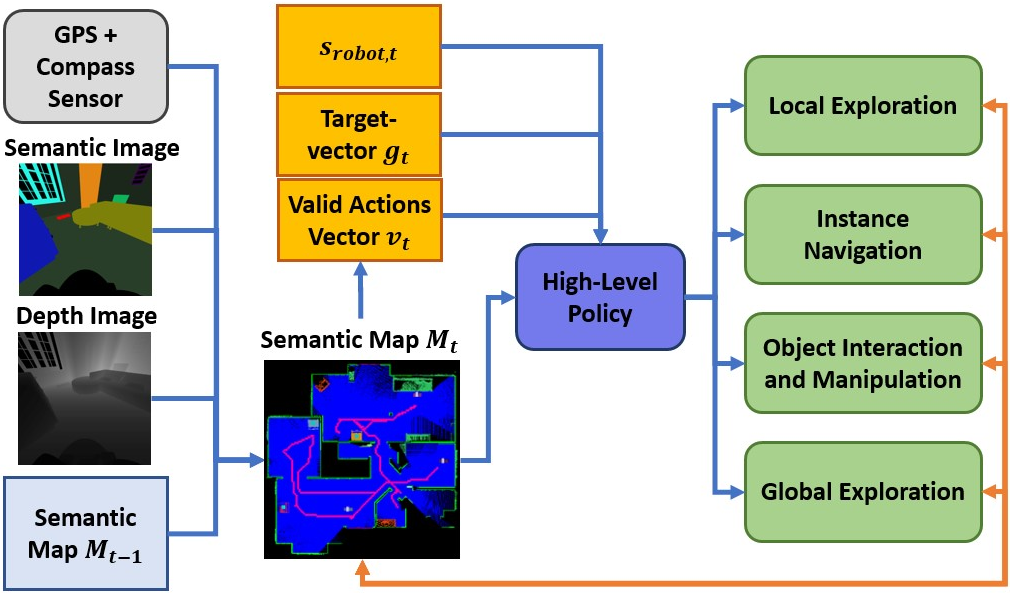
Existing object-search approaches enable robots to search through free pathways, however, robots operating in unstructured human-centered environments frequently also have to manipulate the environment to their needs. In this work, we introduce a novel interactive multi-object search task in which a robot has to open doors to navigate rooms and search inside cabinets and drawers to find target objects. These new challenges require combining manipulation and navigation skills in unexplored environments. We present HIMOS, a hierarchical reinforcement learning approach that learns to compose exploration, navigation, and manipulation skills. To achieve this, we design an abstract high-level action space around a semantic map memory and leverage the explored environment as instance navigation points. We perform extensive experiments in simulation and the real-world that demonstrate that HIMOS effectively transfers to new environments in a zero-shot manner. It shows robustness to unseen subpolicies, failures in their execution, and different robot kinematics. These capabilities open the door to a wide range of downstream tasks across embodied AI and real-world use cases.
Learning Hierarchical
Interactive Multi-Object Search
for Mobile Manipulation
Fabian Schmalstieg*, Daniel Honerkamp*, Tim Welschehold, Abhinav Valada